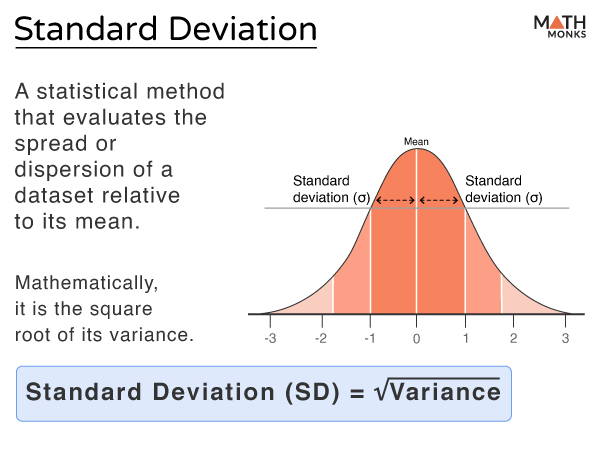
Standard deviation is a statistical measure that shows how much a group of data is spread out or dispersed from its mean value (average). A smaller standard deviation value indicates that the values are close to the mean, whereas a larger value means the dataset is spread out further from the mean.
Mathematically, it is represented by the symbol σ (sigma) and is defined as the square root of the mean of the squares of all the values of a dataset derived from the arithmetic mean.
Formula
Based on the type of data set being analyzed and its context, there are two standard deviations: population and sample standard deviation.
Population Standard Deviation
It is the measure of dispersion for an entire population. It is calculated by the formula:
Since the calculation involves squaring the differences from the mean, the standard deviation is always a positive number or 0.
Statistical data are of two types: ungrouped (raw, unorganized data) and grouped (well-organized data).
We calculate their standard deviations as follows.
For Ungrouped Data
Here are the methods for determining standard deviation, depending on the type of data.
Actual Mean Method
In this method, we first calculate the mean of the given data set. Next, we determine the deviation of each data point from the mean. Finally, we find the standard deviation using the formula:
Thus, the standard deviation is σ = ${\sqrt{Variance}}$ = ${\sqrt{2.5}}$ ≈ 1.58
Assumed Mean Method
This method simplifies calculations by assuming a value close to the large set of data points as the mean, known as the assumed mean (A). The deviation from the assumed mean is calculated using the formula d = x – A.
Finally, we find the standard deviation using the formula:
Just like ungrouped data, we can determine the standard deviation of grouped data by the following methods:
Actual Mean Method
For grouped data, we first construct a frequency distribution. For n number of observations, say x1, x2, …, xn, and the corresponding frequencies, f1, f2, …, fn the standard deviation is calculated as follows:
The following table shows the number of hours students spent studying for a test. Let us calculate the standard deviation of the data using the Assumed Mean Method.
Hours Studied (Interval)
Frequency (fi)
0 -10
4
10 – 20
6
20 – 30
8
30 – 40
10
40 – 50
7
Now, calculating the midpoint (xi) for each interval, we get
A random variable can be either discrete (for countable outcomes) or continuous (for measurable outcomes). For both types, the standard deviation provides the dispersion of a set of values in a probability distribution.
Discrete Random Variables
To determine the standard deviation of a random variable X, we first find the difference between X and the mean or expected value (μ or E(X)) and multiply the result by the probability associated with X. Finally, we take the square root of the product.
The standard deviation of the probability distribution of X is given by ${\sigma =\sqrt{\sum \left[ \left( x-\mu \right) ^{2}\cdot P\left( x\right) \right] }}$
However, there is a shortcut to find the standard deviation of random variables, which is done by the formula:
The method can be applied to discrete or continuous random variables, using either a probability function or a probability density function, as appropriate.
For Common Probability Distributions
Standard deviation varies based on the type of probability distribution:
Normal Distribution
Since the mean is 0, the standard deviation is 1.
Binomial Distribution
The standard deviation is given by:
σ = ${\sqrt{npq}}$
Here,
μ = np is the mean
n is the number of trials
p is the probability of success
q = 1 – p is the probability of failure
Poisson Distribution
The standard deviation is given by:
σ = ${\sqrt{\lambda t}}$
Here,
λ is the average number of successes in an interval of time t
Solved Example
Example 1: There are 25 students in a class. A few students were selected randomly, and their test scores were recorded as follows: 67, 74, 81, 69, 85. Calculate the standard deviation of their scores.